MFCC是干什么的
MFCC(Mel-Frequency Cepstral Coefficients,Mel 频率倒谱系数),语音信号处理中最常用的特征提取方法之一,核心是模拟人类听觉系统对声音的感知特性,将复杂的语音信号转换为低维、鲁棒的频域特征,广泛应用于语音识别、说话人识别、情感识别等领域。
人类听觉(20~20000Hz)对声音的感知并非线性,而是对低频声音的感知更敏感,于是提出Mel刻度来模拟这种特性。
Mel Scale——将实际频率转成基于人耳感知的Mel频率,转换公式:
- 当频率
f ≤ 1000Hz时:Mel(f) = f(低频段 Mel 与 Hz 近似线性) - 当频率
f > 1000Hz时:Mel(f) = 1127 × ln(1 + f/700)(高频段 Mel 与 Hz 呈对数关系)
MFCC理论分析
MFCC的计算原理及步骤:“时域→频域→Mel 域→倒谱域”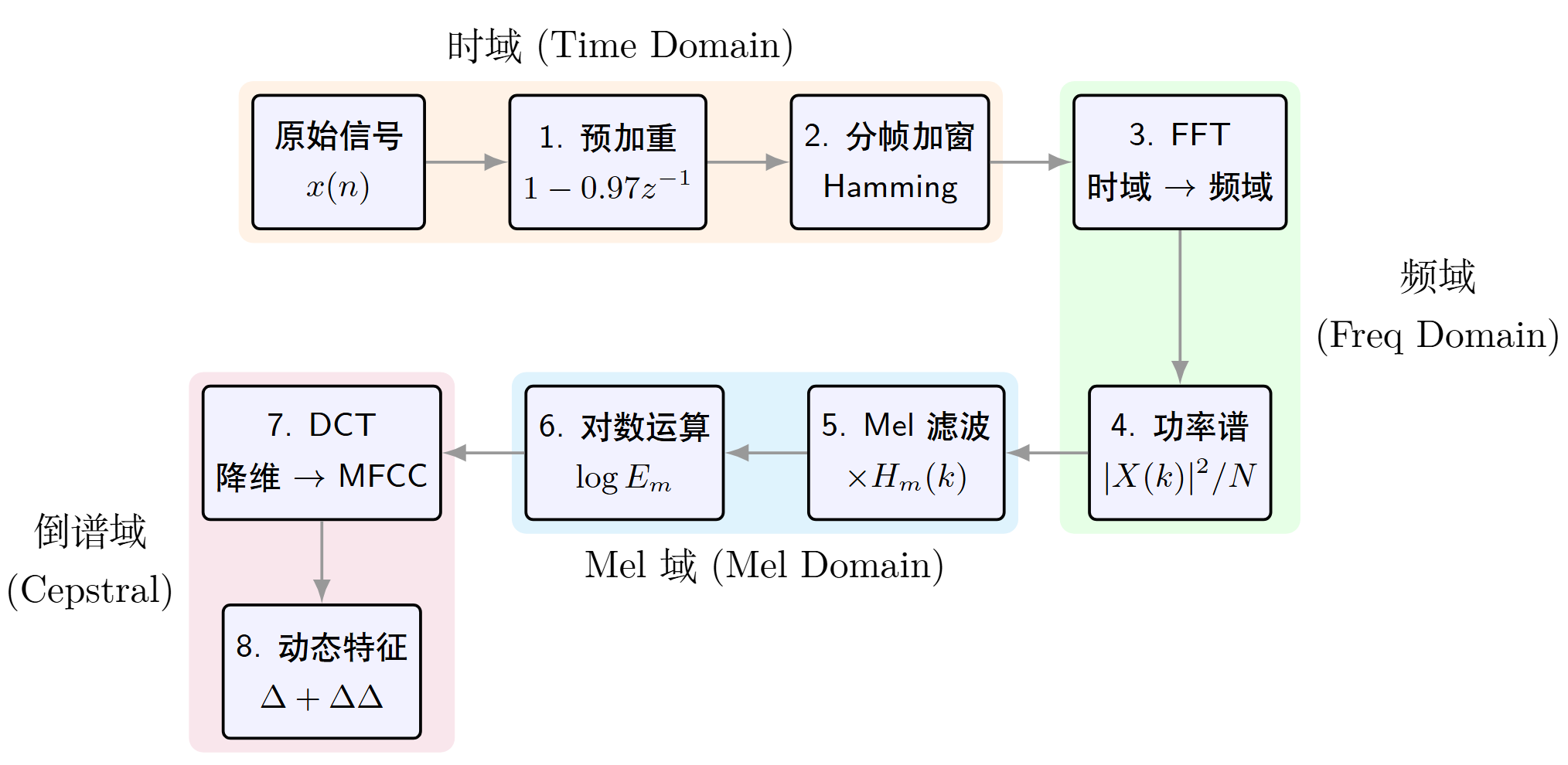
- 语音信号预处理(去直流 + 预加重) 原始语音信号包含直流分量(低频噪声)和高频衰减(高频振动成分会被声道衰减)。
- 去直流分量:减去信号的均值,消除信号整体偏移,避免低频噪声干扰。
- 预加重:(可用一阶高通滤波器
H(z) = 1 - 0.97z⁻¹)增强高频成分,补偿声道的高频衰减,让高低频信号能量更均衡。
- 分帧与加窗(解决 “非平稳性”) 语音信号是短时平稳信号(10~30ms 内特性基本不变,超过则变化明显),因此需要将连续信号切分为 “帧”(Frame)
- 分帧:通常取帧长 20~30ms(如 16kHz 采样率下,一帧含 320~480 个采样点),帧移(相邻帧的重叠)取帧长的 50%(如 160~240 个采样点),避免帧间信息丢失。
- 加窗:对每帧信号乘以汉明窗(Hamming Window) 或汉宁窗(Hanning Window),抑制帧边缘的 “频谱泄漏”(因分帧相当于对信号加矩形窗,会导致频域出现不必要的旁瓣)。
- 快速傅里叶变换(FFT)—— 时域转频域 对每帧加窗后的时域信号做FFT,将其转换为频域的幅度谱(Magnitude Spectrum)
- 目的: 获取信号在不同频率点的能量分布(人类听觉感知的是声音的频率和能量,而非时域波形)。
- 关键:FFT 的点数通常取 2 的幂次(如 512 点),且不小于帧长,确保频域分辨率足够(频率分辨率 = 采样率 / FFT 点数)。
- 计算功率谱(Power Spectrum) 将 FFT 得到的幅度谱平方后除以 FFT 点数,得到功率谱,公式为:(其中 X (k) 是第 k 个频率点的 FFT 结果,N 是 FFT 点数)。
- 意义:功率谱更直接地反映了每个频率点的能量强度,后续处理均基于功率谱进行。
- Mel 滤波器组滤波(映射到 Mel 域) 设计一组符合 Mel 刻度的三角形滤波器组,对功率谱进行滤波,将 “线性频率” 转换为 “Mel 频率”,这是 MFCC 最核心的步骤
- 滤波器组设计规则:
- 滤波器数量通常为 20~40 个(覆盖人类听觉的关键频率范围);
- 滤波器中心频率按 Mel 刻度均匀分布(低频段滤波器密集,高频段稀疏,模拟人耳对低频的敏感特性);
- 每个滤波器是 “三角形”,仅对其中心频率附近的频率点有响应,相邻滤波器在 3dB 处重叠(确保频率覆盖无遗漏)。
- 滤波计算:
- 对每个 Mel 滤波器,计算功率谱在该滤波器频率范围内的加权和(即滤波器输出),公式为:(m=1~M,M 为滤波器数量;H (m,k) 是第 m 个滤波器在第 k 个频率点的权重)。
- 结果:得到 M 个数值,代表语音信号在 M 个 Mel 频率带的能量,即 “Mel 频谱”。
- 对数运算(模拟听觉的对数特性) 人类对声音响度的感知遵循对数规律(声音强度需增加 10 倍,人耳才感觉响度增加 1 倍),因此对每个 Mel 滤波器的输出(S (m))取自然对数或常用对数:(ε 是极小值,避免 S (m)=0 时对数无意义)。
- 离散余弦变换(DCT)—— 降维与去相关性 对对数 Mel 频谱(logS (m))做 DCT 变换,将 M 维的 Mel 频谱转换为 N 维(通常 N=12~16)的倒谱系数,这就是 MFCC 的核心特征。 Mel 频谱的相邻维度(不同 Mel 频率带)存在较强的相关性(因滤波器重叠),DCT 能将相关的 Mel 频谱转换为不相关的倒谱系数,同时起到 “降维” 作用 ——DCT 的前 12~16 个系数(低频倒谱系数)包含了语音的核心特征(如声道共振特性),后面的高频系数主要是噪声,可忽略。
- 结果:得到的 N 个系数称为 “MFCC 系数”,是语音的核心特征
- 动态特征补充(可选但关键) 仅用 MFCC 系数(静态特征)无法反映语音的 “时间变化特性”(如辅音到元音的过渡),实际应用中通常会补充动态特征
- 一阶差分(ΔMFCC):相邻帧 MFCC 系数的差值,反映特征的变化率;
- 二阶差分(ΔΔMFCC):一阶差分的差值,反映特征变化的加速度。
- 最终特征:通常是 “静态 MFCC + ΔMFCC + ΔΔMFCC”(共 36~48 维),能更全面地描述语音的动态特性,显著提升语音识别等任务的性能。
MFCC代码实现
使用 Librosa(python库) 实现
python
import librosa
# import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# 1. 加载音频
#filename = librosa.ex('trumpet') # librosa.ex('trumpet') 是获取自带的测试音频
filename = 'imprisonedXII_v3.wav' # 可以换成自己的文件路径,如 'my_audio.wav'
y, sr = librosa.load(filename)
# y 是一个 numpy 数组,代表音频的波形数据(也叫时间序列),包含了音频随时间变化的振幅值。
# sr 是一个整数,代表采样率 (Sample Rate),表示每秒钟采集了多少个数据点(样本),librosa 默认会将所有音频加载为 22050 Hz
# 2. 提取 MFCC 特征
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
# n_mfcc=13 是最常用的参数,表示提取 13 个系数(通常 13-20 个就足以代表语音特征)
# librosa.feature.mfcc()会自动进行“分帧”处理,n_fft 默认为 2048 个样本,hop_length 滑动步长默认是 512
# 3. 可视化
plt.figure(figsize=(12, 6))
# 绘制热力图
img = librosa.display.specshow(mfccs,
x_axis='time',
sr=sr,
cmap='coolwarm') # cmap='coolwarm' 红蓝配色对比度高
plt.colorbar(img, format='%+2.0f dB')
plt.title('MFCC Visualized (Mel-frequency Cepstral Coefficients)')
plt.ylabel('MFCC Coefficients (0-12)') # Y轴是系数的索引
plt.xlabel('Time (s)')
plt.tight_layout() # 自动调整图表布局
plt.show()
# 4. 打印数据形状,帮助理解
print(f"音频采样率: {sr} Hz")
print(f"音频总时长: {len(y)/sr:.2f} 秒")
print(f"MFCC 矩阵形状: {mfccs.shape} (系数数量 x 时间帧数)")输出图像:C0-C12
输出结果:
音频采样率: 22050 Hz
音频总时长: 194.04 秒
MFCC 矩阵形状: (13, 8357) (系数数量 x 时间帧数)
结果分析:
- C0 (最底下一行) 是深蓝色(比如 -500),它是一个累加的基准值。
- C1-C12 (上面几行) 颜色偏红/橙(在 0 附近),它们代表的是相对变化。
- 看颜色条 (Colorbar)
- 红色/深红 (+100 dB):数值最大。通常代表某些频段能量特别突出,或者经过了某种归一化处理变成了正数。
- 橙色/浅色 (0 dB):数值居中。
- 深蓝 (-500 dB):数值最小(最负)。代表能量很低,或者是 C0 这种累加出来的负偏移量
- 看 C0 (最底下的蓝色条带)
- 现象:最底下一行是蓝色的。
- 动态变化:仔细看蓝色条带内部,颜色变浅(变白/变淡蓝)的地方,代表那一刻声音变大了;颜色变得更深蓝的地方,代表那一刻声音变小了。
- C. 看 C1-C12 (上面的橙色部分)
- 含义:这些纹理代表音色。比如,当在发 "a" 这个音时,纹理是一种图案;发 "s" 时,纹理会变。
- Librosa 图的问题:因为底下的 C0 太负了(-500),强行拉宽了整个色阶范围,导致上面 C1-C12 的细微变化(可能只有 -20 到 20 的波动)在图中看不清楚,糊成了一片橙色。
手动实现
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from scipy.fftpack import dct
# ==========================================
# 0. 准备工作 & 参数设置
# ==========================================
filename = 'imprisonedXII_v3.wav' # 请确保文件存在,且为WAV格式
# 如果没有文件,可以生成一个简单的正弦波测试
# fs = 22050
# signal = np.sin(2 * np.pi * 440 * np.linspace(0, 2, 2*fs))
# 使用 scipy 读取 wav (替代 librosa.load)
sample_rate, signal = wavfile.read(filename)
# 归一化信号到 -1 ~ 1 之间 (librosa 默认会做这个,scipy 读取的是整数)
signal = signal / np.max(np.abs(signal))
# 只取前 3.5 秒 (为了演示方便,防止数据过大)
# signal = signal[:int(3.5 * sample_rate)]
# MFCC 参数
pre_emphasis = 0.97
frame_size = 0.025 # 25ms
frame_stride = 0.01 # 10ms (即 hop_length)
NFFT = 512 # FFT 点数
nfilt = 40 # Mel 滤波器组的数量
num_ceps = 13 # 保留的 MFCC 系数数量
# ==========================================
# 1. 预加重 (Pre-emphasis)
# 目的:提升高频部分,平衡频谱,因为语音信号高频能量通常较低
# 公式:y(t) = x(t) - alpha * x(t-1)
# ==========================================
emphasized_signal = np.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
# ==========================================
# 2. 分帧 (Framing)
# 目的:语音信号在短时间内(20-30ms)是平稳的
# ==========================================
frame_length = int(round(frame_size * sample_rate))
frame_step = int(round(frame_stride * sample_rate))
signal_length = len(emphasized_signal)
num_frames = int(np.ceil(float(np.abs(signal_length - frame_length)) / frame_step))
pad_signal_length = num_frames * frame_step + frame_length
z = np.zeros((pad_signal_length - signal_length))
pad_signal = np.append(emphasized_signal, z)
# 构建索引矩阵
indices = np.tile(np.arange(0, frame_length), (num_frames, 1)) + \
np.tile(np.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[indices.astype(np.int32, copy=False)]
# ==========================================
# 3. 加窗 (Windowing)
# 目的:减少频谱泄露,通常使用汉明窗 (Hamming Window)
# ==========================================
frames *= np.hamming(frame_length)
# ==========================================
# 4. FFT 和 功率谱 (Power Spectrum)
# 目的:时域 -> 频域
# ==========================================
mag_frames = np.absolute(np.fft.rfft(frames, NFFT)) # Magnitude of the FFT
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum
# ==========================================
# 5. Mel 滤波器组 (Mel Filter Bank)
# 目的:模拟人耳对频率的感知(低频敏感,高频不敏感)
# ==========================================
low_freq_mel = 0
high_freq_mel = (2595 * np.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Mel
mel_points = np.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10**(mel_points / 2595) - 1)) # Convert Mel to Hz
bin = np.floor((NFFT + 1) * hz_points / sample_rate)
fbank = np.zeros((nfilt, int(np.floor(NFFT / 2 + 1))))
# 构建三角滤波器
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # 左边界
f_m = int(bin[m]) # 中心峰值
f_m_plus = int(bin[m + 1]) # 右边界
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
# 将滤波器应用到功率谱上
filter_banks = np.dot(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks) # Numerical Stability
# ==========================================
# 6. 对数运算 (Log)
# 目的:人耳对响度的感知是对数关系的
# ==========================================
filter_banks = 20 * np.log10(filter_banks) # dB
# ==========================================
# 7. 离散余弦变换 (DCT)
# 目的:去相关性,将能量集中在低阶系数
# ==========================================
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)] # Keep 1-13
# (可选) 正弦提升 (Sinusoidal Liftering) - 通常用于平滑MFCC
(nframes, ncoeff) = mfcc.shape
n = np.arange(ncoeff)
lift = 1 + (22 / 2) * np.sin(np.pi * n / 22)
mfcc *= lift
# ==========================================
# 可视化 (不使用 librosa.display)
# ==========================================
plt.figure(figsize=(12, 6))
# 这里的 MFCC 需要转置一下才能让时间轴在 X 轴
# origin='lower' 确保低频(系数索引0)在底部
plt.imshow(mfcc.T, cmap='coolwarm', aspect='auto', origin='lower', extent=[0, len(signal)/sample_rate, 0, num_ceps ])
plt.yticks(np.arange(1, num_ceps + 1)) # y轴刻度为1,2,...,num_ceps
plt.title('MFCC (Implemented from Scratch)')
plt.ylabel('MFCC Coefficients')
plt.xlabel('Time (s)')
plt.colorbar(format='%+2.0f')
plt.tight_layout()
plt.show()
print(f"音频采样率: {sample_rate} Hz")
print(f"音频总时长: {len(signal)/sample_rate:.2f} 秒")
print(f"MFCC 矩阵形状: {mfcc.T.shape} (系数数量 x 时间帧数)")结果图像:C1-C13
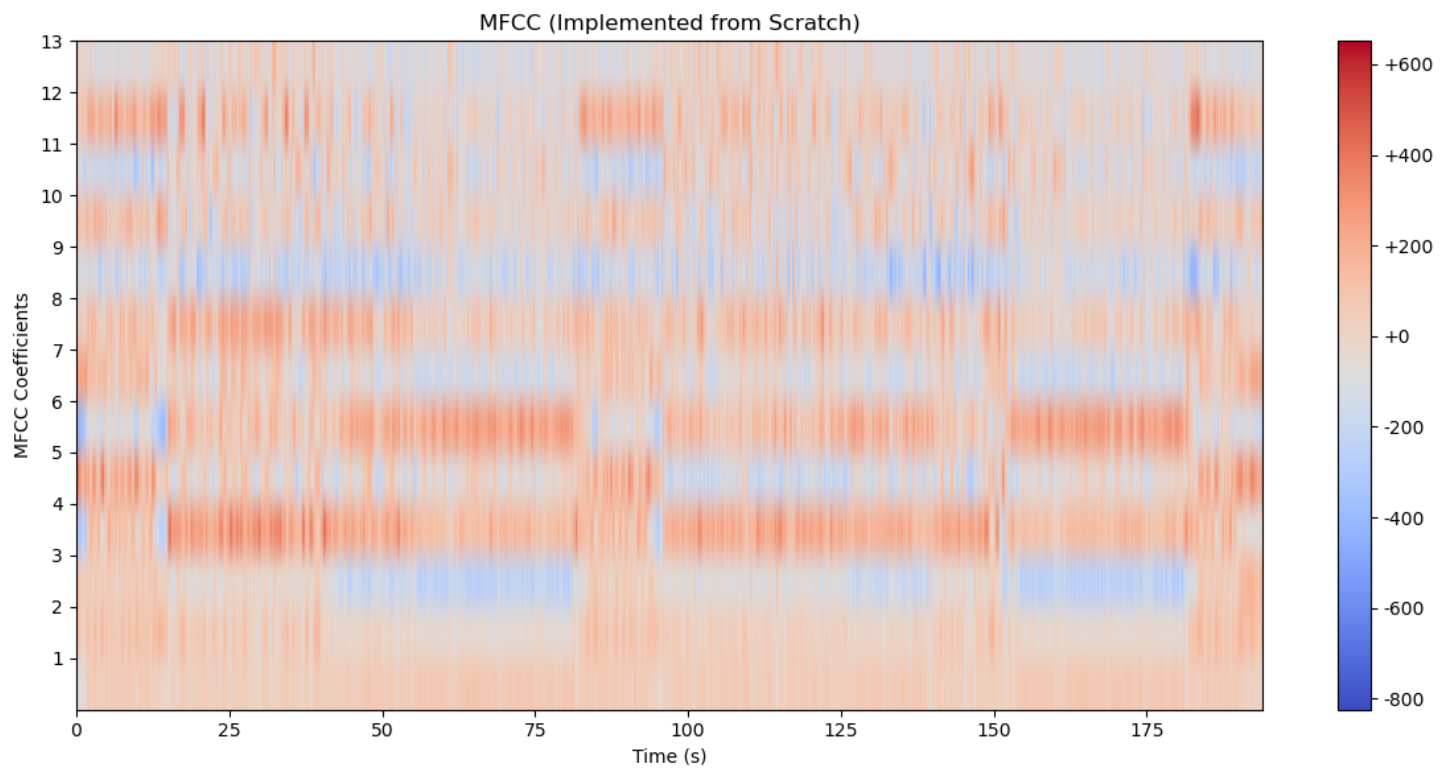
输出:
音频采样率: 44100 Hz
音频总时长: 194.04 秒
MFCC 矩阵形状: (13, 38806) (系数数量 x 时间帧数)


